Biosynthèse des protéines
La biosynthèse des protéines est l'ensemble des processus biochimiques permettant aux cellules de produire leurs protéines à partir de leurs gènes afin de compenser les pertes en protéines par sécrétion ou par dégradation. Elle recouvre les étapes de transcription de l'ADN en ARN messager, d'aminoacylation des ARN de transfert, de traduction de l'ARN messager en chaînes polypeptidiques, de modifications post-traductionnelles de ces dernières, et enfin de repliement des protéines ainsi produites. Elle est étroitement régulée à de multiples niveaux, principalement lors de la transcription et lors de la traduction.



Le matériel génétique des cellules est constitué d'ADN sur lequel l'information génétique est organisée en gènes, ou cistrons, et encodée sous forme de codons consécutifs de trois nucléotides. Chaque codon correspond à un acide aminé précis : la correspondance entre codons et acides aminés constitue le code génétique. La biosynthèse des protéines consiste à synthétiser une chaîne polypeptidique dont la séquence peptidique est déterminée par la séquence nucléotidique — et donc la succession des codons — du gène correspondant. Pour ce faire, l'ADN est tout d'abord transcrit en ARN messager par une ARN polymérase. Chez les eucaryotes, cet ARN messager subit une série de modifications post-transcriptionnelles — ajout d'une coiffe, polyadénylation, épissage — puis gagne le cytoplasme à travers les pores nucléaires. Parallèlement, dans le cytoplasme, les acides aminés sont activés chacun sur leur ARN de transfert par leur aminoacyl-ARNt synthétase spécifique : il existe un type d'ARN de transfert et une aminoacyl-ARNt synthétase spécifique pour chacun des acides aminés protéinogènes. Chaque ARN de transfert étant différent, il possède un anticodon spécifique, composé de trois nucléotides formant une séquence complémentaire d'un codon d'ARN messager : c'est cette spécificité qui assure la correspondance entre un codon donné et un acide aminé unique lié à un ARN de transfert déterminé.
Une fois dans le cytoplasme, les ARN messagers sont lus séquentiellement par des organites spécialisés appelés ribosomes, formés d'ARN ribosomiques complexés avec plus d'une cinquantaine de protéines différentes. Ces ribosomes assemblent les acides aminés au fur et à mesure qu'ils parcourent les codons de l'ARN messager, réalisant ainsi la traduction de ce dernier : les aminoacyl-ARNt se lient séquentiellement aux codons de l'ARN messager par leur anticodon, et le ribosome catalyse la formation d'une liaison peptidique entre la chaîne polypeptidique naissante et l'acide aminé apporté par l'ARN de transfert. De cette façon, la séquence peptidique des protéines correspond fidèlement à la séquence nucléotidique des gènes exprimés. Chez les eucaryotes, la traduction de l'ARN messager en protéines par les ribosomes se déroule dans le cytoplasme de la cellule pour les protéines cytoplasmiques, ou dans le réticulum endoplasmique dit rugueux pour les protéines vouées à être sécrétées ou membranaires. Elle est éventuellement suivie de modifications post-traductionnelles, comme la glycosylation (liaison covalente d'oses), dans l'appareil de Golgi, qui constituent un élément important de la signalisation cellulaire. Chez les procaryotes, la transcription de l'ADN en ARN messager et la traduction de ce dernier en protéines ont lieu dans le cytoplasme et peuvent être simultanées, la traduction débutant alors que la transcription n'est pas encore achevée. Cette simultanéité donne lieu à un important type de régulation de la traduction.
Les protéines fonctionnelles sont le plus souvent synthétisées à partir des gènes par traduction directe d'un ARN messager. Cependant, lorsqu'une protéine doit être produite très rapidement ou en grande quantité, c'est tout d'abord un précurseur protéique qui est produit par l'expression du gène. On appelle proprotéine une protéine inactive possédant un ou plusieurs peptides inhibiteurs ; elle peut être activée pour donner une protéine fonctionnelle en clivant ce peptide inhibiteur par protéolyse lors d'une modification post-traductionnelle. On appelle préprotéine une forme contenant un peptide signal à son extrémité N-terminale qui spécifie son insertion dans ou à travers une membrane et la désigne pour être sécrétée ; ce peptide signal est clivé dans le réticulum endoplasmique. On appelle préproprotéine une forme possédant à la fois un peptide signal et un peptide inhibiteur.
Transcription de l'ADN en ARN
modifier
La première étape de la synthèse des protéines est la transcription d'un gène d'ADN en une molécule d'ARN messager (ARNm). L'ARN a une structure très proche de celle de l'ADN, mais est monocaténaire tandis que l'ADN tend à former des structures bicaténaires, l'ose y est le ribose au lieu du désoxyribose, et l'uracile y remplace la thymine. Ce processus se déroule à l'intérieur même du noyau des cellules d'eucaryotes et dans le cytosol des cellules de procaryotes ; cette différence a des conséquences importantes sur le traitement de l'ARN synthétisé. Chez les eucaryotes, le fait que l'ARN gagne le cytoplasme à travers les pores nucléaires est à l'origine de la dénomination d'ARN « messager". La transcription peut être divisée en trois étapes : initiation, élongation et terminaison, chacune régulée par un grand nombre de protéines, telles que des facteurs de transcription et des coactivateurs qui assurent que le bon gène est bien transcrit. L'initiation commence à partir d'un promoteur, c'est-à-dire d'une séquence nucléotidique recouvrant des séquences typiques telles que la boîte TATA (séquence consensus TATAA) chez les eucaryotes et la boîte de Pribnow (séquence consensus TATAAT) chez les procaryotes. Ces séquences sont riches en paires adénine-thymine, unies par seulement deux liaisons hydrogène, à la différence des paires guanine-cytosine qui sont unies par trois liaison hydrogène : ceci facilite l'ouverture de la double hélice d'ADN par une hélicase, libérant l'un des deux brins pour être copié en ARN. Une ARN polymérase (ARN polymérase II chez les eucaryotes) lit ce segment d'ADN dans le sens 3’ → 5’ tout en synthétisant l'ARN messager dans le sens 5’ → 3’.
Tous les gènes d'une cellule n'encodent pas nécessairement des protéines : un très grand nombre d'entre eux encodent des ARN dits « non codants » car il s'agit non pas d'ARN messager porteurs codons d'acides aminés mais, par exemple, d'ARN ribosomique ou d'ARN de transfert, de sorte que l'ARN messager constitue une partie seulement de l'ARN issue de la transcription des gènes par des ARN polymérases. Chez les procaryotes, le produit de la transcription d'un gène de protéine est directement utilisable comme ARN messager. Chez les eucaryotes, en revanche, on parle de transcrit primaire, qui doit encore subir un certain nombre de modifications post-transcriptionnelles constituant la maturation de l'ARN messager, avant de devenir fonctionnel.
Modifications post-transcriptionnelles
modifierLes principales modifications post-transcriptionnelles de l'ARN pré-messager sont l'ajout d'une coiffe de 7-méthylguanosine triphosphate à l'extrémité 5' et d'une queue poly(A) (50 à 250 nucléotides d'adénine) à l'extrémité 3', puis l'épissage, consistant en l'élimination des introns (segments du gène qui ne codent pas un polypeptide) séparant les exons (qui, eux, sont codants). Cet épissage peut être variable (épissage alternatif).
-
 Structure d'un ARN messager typique d'eucaryote, comprenant la coiffe, la région 5’ non traduite, la région codante entre le codon d'initiation et le codon stop, la région 3’ non traduite, et la queue de poly(A).
Structure d'un ARN messager typique d'eucaryote, comprenant la coiffe, la région 5’ non traduite, la région codante entre le codon d'initiation et le codon stop, la région 3’ non traduite, et la queue de poly(A).


L'ARN messager peut alors être traduit.
Traduction de l'ARN messager en protéine
modifierUne fois que le brin d'ARN messager a atteint le cytoplasme, où a lieu la traduction, il se lie à un ribosome. Ce dernier est un organite constitué d'une sous-unité 60S et d'une sous-unité 40S chez les eucaryotes, et d'une sous-unité 50S et d'une sous-unité 30S chez les procaryotes. Les ribosomes sont des complexes de protéines et d'ARN dits ARN ribosomiques. Ils assemblent les acides aminés pour former les protéines en fonction de la séquences nucléotidique de l'ARN messager, chaque codon de cette séquence correspondant à un acide aminé de la protéine en cours de synthèse.
Les ribosomes possèdent trois sites notables, notés A, P et E :
- le site A (pour « Acide aminé »), situé sur la petite sous-unité ribosomique, est celui sur lequel l'aminoacyl-ARNt correspondant au codon d'ARNm en cours de lecture vient se lier au complexe ribosome-ARNm ;
- le site P (pour « Peptide »), situé sur la grande sous-unité ribosomique, est celui sur lequel se fixe la chaîne polypeptidique naissante, liée à l'ARNt correspondant au codon précédant celui en cours de lecture ;
- le site E (pour « Exit ») est celui sur lequel vient se fixer l'ARNt débarrassé de la chaîne polypeptidique naissante lorsque celle-ci est transférée depuis le site P vers l'aminoacyl-ARNt du site A.
Activation des acides aminés sur leur ARN de transfert
modifierAfin d'être incorporé dans une protéine, un acide aminé protéinogène doit préalablement être fixé par une liaison ester à l'extrémité 3’ de l'ARN de transfert correspondant. Cette activation est réalisée par une aminoacyl-ARNt synthétase. Il existe autant d'ARN de transfert et d'aminoacyl-ARNt synthétases qu'il y a d'acide aminés. Parmi les 22 acides aminés protéinogènes, seule la sélénocystéine fait exception, car elle est produite directement sur son ARN de transfert à partir de la sérine.
-
 Configuration tridimensionnelle de l'ARNt de phénylalanine chez Saccharomyces cerevisiae (PDB 1EHZ).
Configuration tridimensionnelle de l'ARNt de phénylalanine chez Saccharomyces cerevisiae (PDB 1EHZ). -
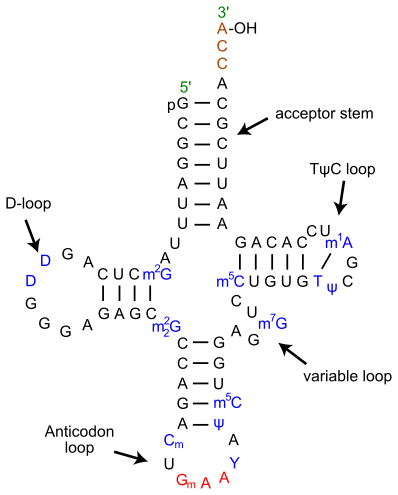 (en) ARNt de phénylalanine chez la levure, indiquant l'anticodon en rouge et l'hydroxyle 3’–OH estérifié par l'acide aminé en haut.
(en) ARNt de phénylalanine chez la levure, indiquant l'anticodon en rouge et l'hydroxyle 3’–OH estérifié par l'acide aminé en haut.


Initiation
modifierLa biosynthèse de la chaîne polypeptidique commence généralement au niveau d'un codon AUG, encodant la méthionine. Chez les procaryotes, c'est un résidu de N-formylméthionine qui est incorporé en position initiale, tandis que, chez les eucaryotes, c'est un résidu de méthionine, qui peut être clivé par la suite. Il existe deux ARN de transferts distincts selon que le codon AUG est un codon d'initiation ou un codon d'élongation.
Le codon d'initiation peut être différent du codon AUG : il peut s'agir par exemple des codons CUG et UUG, qui encodent normalement la leucine, mais, lorsqu'ils sont lus comme codons d'initiation, sont interprétés comme codons de méthionine.
Élongation
modifierLe ribosome parcourt le brin d'ARN messager codon par codon (translocation) et ajoute, par l'intermédiaire d'un ARN de transfert (ARNt), un acide aminé à la protéine en cours de synthèse en fonction du codon en cours de lecture. La protéine est produite en commençant par l'extrémité N-terminale et en terminant par l'extrémité C-terminale. Le ribosome progresse le long de l'ARN messager sous l'action de facteurs d'élongation, qui tirent leur énergie de l'hydrolyse d'une molécule de GTP.
Plus précisément, les protéines EF-Tu (43 kDa) chez les procaryotes et eEF-1α (53 kDa) chez les eucaryotes se lient à l'aminoacyl-ARNt dans le cytoplasme et accompagnent ce dernier jusqu'à l'entrée du site A du ribosome ; si l'anticodon de l'ARNt correspond au codon de l'ARNm alors les protéines EF-Tu ou eEF-1α hydrolysent une molécule de GTP (accommodation), ce qui a pour effet de les détacher de l'aminoacyl-ARNt et de pousser ce dernier entièrement dans le site A. Ceci a pour effet de rapprocher la chaîne polypeptidique naissante, fixée à un ARNt lié au site P du ribosome, du résidu d'acide aminé de l'aminoacyl-ARNt lié au site A : le ribosome catalyse alors la formation d'une liaison peptidique, qui aboutit au transfert de la chaîne peptidique, allongée d'un acide aminé, sur l'ARNt lié au site A (transpeptidation), laissant l'ARNt du site P libre de toute liaison avec un acide aminé.
Puis les protéines EF-G (77 kDa) chez les procaryotes et eEF-2 (70-110 kDa) chez les eucaryotes, autrefois appelées translocases, poussent le peptidyl-ARNt du site A vers une position intermédiaire avec le site P, d'où l'ARNt du site P est également poussé vers une position intermédiaire avec le site E. L'hydrolyse d'une seconde molécule de GTP achève ce mouvement (translocation), en poussant le peptidyl-ARNt vers le site P et l'ARNt libre vers le site E : ce dernier quitte le ribosome, qui se déplace de trois nucléotides — c'est-à-dire d'un codon — le long de l'ARN messager. Le site A est alors libre d'accueillir un nouvel aminoacyl-ARNt en face du codon suivant.
Terminaison
modifierUne fois un codon-stop atteint (UAA, UGA ou UAG), la synthèse de la protéine est terminée : le ribosome se détache de la protéine et du brin d'ARN messager, et la protéine est libérée dans la cellule. Le ribosome se scinde en ses deux sous-unités et peut conduire une autre synthèse sur un autre ARN messager. S'entame alors le transport des protéines, qui peut les mener hors de la cellule et dans le système sanguin, ou encore à l'intérieur même de la cellule les ayant synthétisées.
Le même brin d'ARN messager peut servir à la biosynthèse simultanée de plusieurs molécules de protéines, lorsque plusieurs ribosomes s'en chargent. Avant d'être détruite, cette molécule participe à la synthèse d'environ 10 à 20 protéines.
Exemple
modifierLe brin d'ARN messager est : A U G G C G U U C A G A A C U G A U A C G U A A Les différents codons sont donc : AUG · GCG · UUC · AGA · ACU · GAU · ACG · UAA Les ARN de transfert se fixent UAC CGC AAG UCU UGA CUA UGC codon-stop par complémentarité et apportent | | | | | | | reconnu par les les acides aminés appropriés : Met Ala Phe Arg Thr Asp Thr facteurs de terminaison
Table des acides aminés en fonction des codons
modifierChaque codon qui n'est pas un codon-stop encode un acide aminé protéinogène ; certains codons-stop peuvent également, dans certaines circonstances, encoder des acides aminés. La correspondance entre codons et acides aminés est la base du code génétique :
| 1re base |
2e base | 3e base | |||||||
|---|---|---|---|---|---|---|---|---|---|
| U | C | A | G | ||||||
| U | UUU | F Phe
|
UCU | S Ser
|
UAU | Y Tyr
|
UGU | C Cys
|
U |
| UUC | F Phe
|
UCC | S Ser
|
UAC | Y Tyr
|
UGC | C Cys
|
C | |
| UUA | L Leu
|
UCA | S Ser
|
UAA | Stop ocre | UGA | Stop opale / U Sec / W Trp
|
A | |
| UUG | L Leu / initiation
|
UCG | S Ser
|
UAG | Stop ambre / O Pyl
|
UGG | W Trp
|
G | |
| C | CUU | L Leu
|
CCU | P Pro
|
CAU | H His
|
CGU | R Arg
|
U |
| CUC | L Leu
|
CCC | P Pro
|
CAC | H His
|
CGC | R Arg
|
C | |
| CUA | L Leu
|
CCA | P Pro
|
CAA | Q Gln
|
CGA | R Arg
|
A | |
| CUG | L Leu / initiation
|
CCG | P Pro
|
CAG | Q Gln
|
CGG | R Arg
|
G | |
| A | AUU | I Ile
|
ACU | T Thr
|
AAU | N Asn
|
AGU | S Ser
|
U |
| AUC | I Ile
|
ACC | T Thr
|
AAC | N Asn
|
AGC | S Ser
|
C | |
| AUA | I Ile
|
ACA | T Thr
|
AAA | K Lys
|
AGA | R Arg
|
A | |
| AUG | M Met & initiation
|
ACG | T Thr
|
AAG | K Lys
|
AGG | R Arg
|
G | |
| G | GUU | V Val
|
GCU | A Ala
|
GAU | D Asp
|
GGU | G Gly
|
U |
| GUC | V Val
|
GCC | A Ala
|
GAC | D Asp
|
GGC | G Gly
|
C | |
| GUA | V Val
|
GCA | A Ala
|
GAA | E Glu
|
GGA | G Gly
|
A | |
| GUG | V Val
|
GCG | A Ala
|
GAG | E Glu
|
GGG | G Gly
|
G | |
À partir de 20 AA différents, on peut synthétiser 20 puissance 2 dipeptides, soit 400. 20 puissance 3 tripeptides, soit 8000 etc. Pour une proteine comportant 500 AA,ce qui correspond à des protéines tout à fait courantes, on arrive à 20 puissance 500. Cette présentation permet de donner toute sa valeur à la précision indispensable de la transcription et de la traduction pour que la cellule puisse synthétiser les protéines qui lui sont nécessaires. Si à un AA peuvent correspondre plusieurs codons (code redondant), à un codon ne peut correspondre qu'un AA spécifique.
Modifications post-traductionnelles
modifierLes chaînes polypeptidiques nouvellement synthétisées par les ribosomes peuvent subir des modifications post-traductionnelles qui étendent le répertoire des 22 acides aminés protéinogènes en modifiant chimiquement les chaînes latérales de certains résidus. Il peut s'agir par exemple de lier par covalence des groupes fonctionnels tels que phosphate (phosphorylation), acétate (acétylation) ou méthyle (méthylation), voire des oses, des oligosaccharides ou des polysaccharides (glycosylation), ou encore des lipides (prénylation).
D'autres formes de modifications post-traductionnelles consistent à cliver certaines liaisons peptidiques, par exemple d'un précurseur protéique pour former une protéine fonctionnelle, comme c'est par exemple le cas de l'insuline, qui est clivée deux fois après la formation des ponts disulfure.
-
 (en) Maturation de la protéine sonic hedgehog (SHH).
(en) Maturation de la protéine sonic hedgehog (SHH).

Mise en évidence du mécanisme global de synthèse
modifierPour découvrir la succession d'étapes qui mène à l'achèvement des protéines, les biologistes utilisent comme technique principale celle du pulse-chase ou pulse-chasse, qui se déroule en quatre grandes étapes.
On prélève à intervalles réguliers des cellules de ce nouveau milieu ; on dispose alors de deux techniques d'exploitation de cette expérience. La première est l'autoradiographie ; la seconde passe par une ultracentrifugation et donne une meilleure précision dans les résultats. On prépare une coupe de la cellule, par fixation puis découpage au microtome. Sur la plaquette obtenue, on dépose un film photographique contenant des grains d'argent, et on laisse le tout reposer quelques semaines à l'obscurité. Les électrons issus de la désintégration des noyaux radioactifs assimilés par la cellule réduisent les ions Ag+ en grains noirs d'argent, donnant ainsi une « photographie » de la localisation de la radioactivité cellulaire. On peut ainsi retracer, par observation de lames minces à temps de « chasse » différents, le trajet cellulaire des protéines lors de leur synthèse. Cependant, les électrons de la lame mince peuvent marquer la plaque photographique assez loin de leur zone d'émission (précision de l'ordre du demi-micromètre). Ainsi, on ne peut pas savoir par exemple, si la radioactivité dans un organite est à l'intérieur ou éventuellement juste à l'extérieur de ses parois. On centrifuge à haute vitesse chaque prélèvement de cellules du second milieu. On obtient ainsi, après plusieurs centrifugations successives à des accélérations croissantes, différentes fractions de cellule, classées suivant leur masse. On connaît la correspondance entre les divers organites (réticulum endoplasmique, appareil de Golgi, noyau) et les fractions après centrifugations. Ainsi, si on mesure la radioactivité de chaque fraction, on peut savoir dans quel organite les acides aminés marqués se trouvaient au moment du prélèvement. On en déduit des courbes de répartition de radioactivité en fonction du temps pour chaque compartiment cellulaire, ce qui permet de retrouver le trajet des acides aminés nouvellement assemblés en protéines..
Sources
modifier- Neil A. Campbell et Jane B. Reece, Biologie, traduit par Richard Mathieu, Éd. Éditions du Renouveau Pédagogique Inc., Saint-Laurent (Québec), , 1400 p. (ISBN 2-7613-1379-8).
Voir aussi
modifierArticles connexes
modifier- Cellule
- Protéine
- Génétique > ADN > Gène > ARN > Synthèse des protéines
- Transcription
- Traduction
Liens externes
modifier- Baptiste Deleplace (2003), La traduction (une approche ludique de la traduction de l'ARN m en chaîne polypeptidique).
- Encyclopédie Vulgaris Médical : ADN et synthèse d'une protéine